Date: 2026-01-12 Lecture Cluster 10B Week 2 Lecture Notes
Notes
Monday
Prof Miriam Posner
How Does ChatGPT Work
- Conversations about AI tend to be more productive if we have more specificity about what we are talking about and how they work
- One way that humans learn is activating prior knowledge in order to learn
- ChatGPT relies on a technology called a large language model. LLMs are the results of decades of scholarship and are very complex
- AI is a larger domain of computer research and refers to any effort to make a computer act like a human being - The broad field
- Machine learning is a sub discipline
- Deep learning is a sub sub discipline that used multilayers neural nets or a deep learning network
- A Large language model is a package of statistics that documents or models language
- LLMs make use of neural nets which is a specific approach approach to machine learning

- Deep learning is a sub sub discipline that used multilayers neural nets or a deep learning network
- Machine learning is a sub discipline
Expert systems/Knowledge Engineering 1970-1995
- Find human experts in different domains and seek to document their expertise using interview
- draw up a set of rules based on those interviews and then formalize and revise
- Encode these rules technically and use them to simulate processes of human reasoning
Machine Learning Approach to AI
- In the wild robot they have a good example of the machine learning approach to AI
- Machine learning needs labelled training data in order to identify patterns and “learn”
- GPT is a giant package of statistics about the probability of words occurring in a certain order
- Answer the question about what is the probability that the next word will be the next word, generates these words recursively, looks at the entire sentence altogether
What is Involved in Creating an LLM Based Chatbot
- Need a bunch of data
- GPT gets it’s data about language from the internet, scan books, etc.
- This is called the corpus that is used to train the model
- Washington post websites included in ChatGPT
- Also includes pirated books
- Meta torrented Libgen library
- Need to train the model
Rise of Neural Networks
- Was originally developed in the 60s 70s
- Fell out of fashion
- In the 90s came back with the failure of expert systems, advent of more data and more compute
- Deep Neural network
- Input layer
- Multiple hidden layers (deep networks may have millions of layers)
- output layer
- Many variants of neural networks that have been shown to be useful for different things
- A neuron is a thing that holds a number between 0 and 1 usually the number is scaled to between 0 and 1 because of a sigmoid function
- layer of neuron represents a set of features which will activate different neurons
- Forward propagation
- feedforward
- Backpropogation
- the way that a neural network learns is backward propagation
- this is the optimization step, will be tested against some real data or ground truth and the loss function is calculated, the success of the model in training and the ground truth
- the loss function gets set back through the nerual network and the weights and biases of each neuron are altered in some way and this is how the network adjusts and optimizes
- We technically don’t know what is happening in the hidden layers and this is why people are working on interpretability and explainability
- Given that LLMs ar fundamentally math why don’t they always produce the same content
- Many different probable answers
- There is randomness built in
- Deterministic vs stochastic
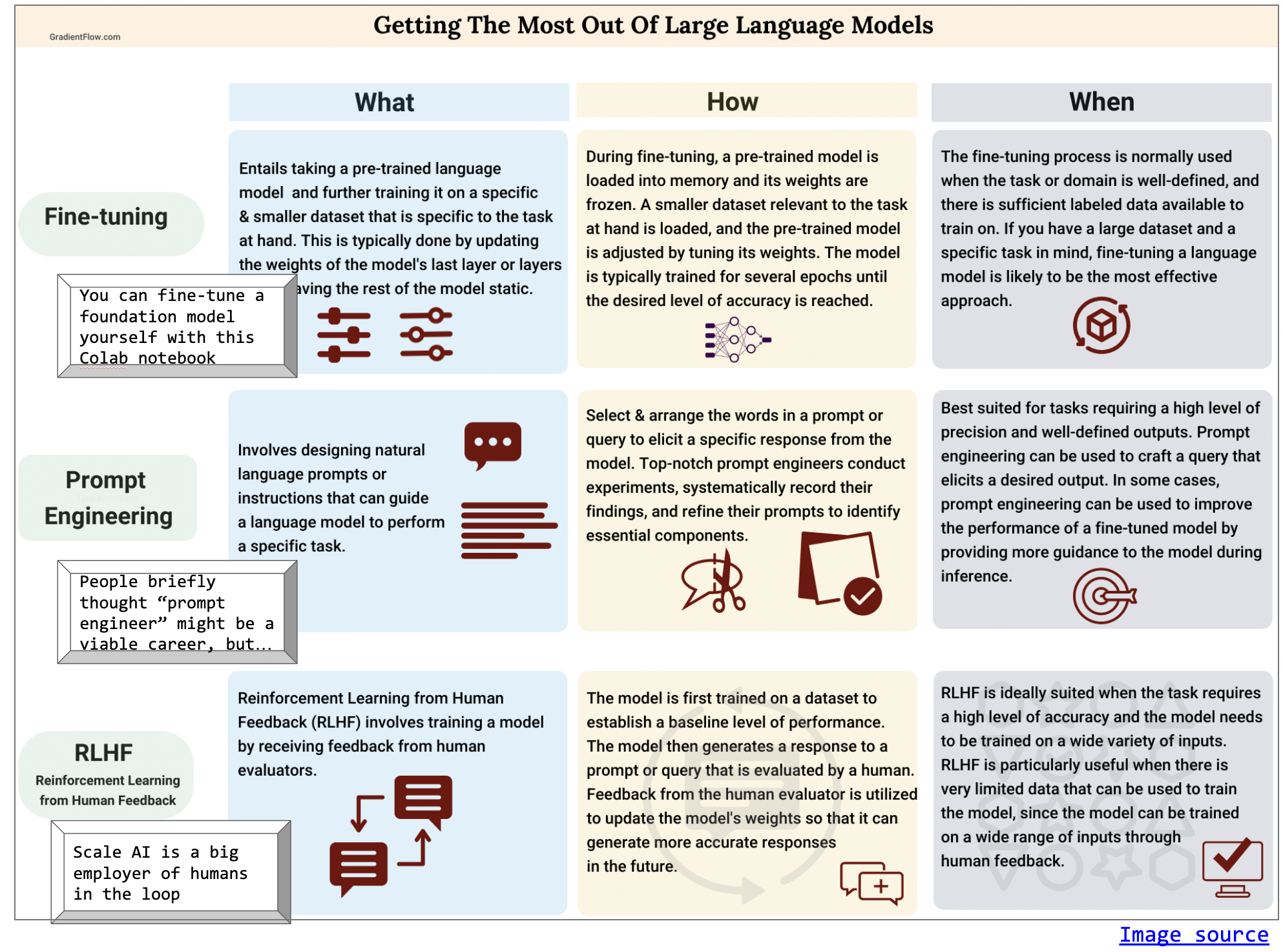
Getting the Most out of LLMs
- Fine tuning
- Prompt Engineering
- RLHF
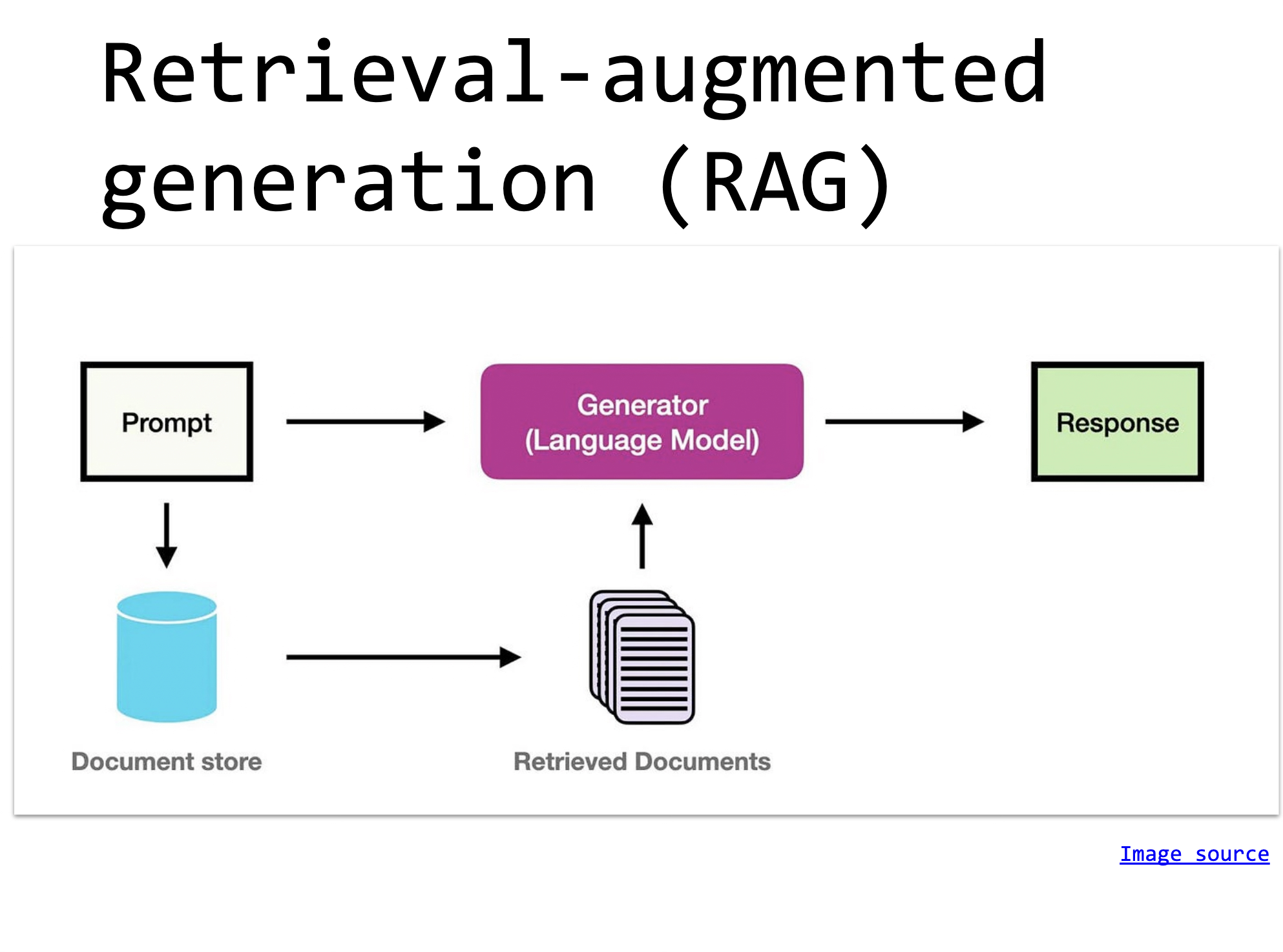
RAG
- Retrieval Augmented Generation
Wednesday
Prof. Munia Bhaumik
What is Missing is Still there - Missing Datasets
- We don’t often think about the humanities as central to questions about data, but Prof Bhaumik argues that the humanities is a very important place to think about data
- Du Bois is an example of where data and art coalesce
Keywords
- Missing data
- Error
- Bias
Key Questions for This Course
- pivoting to analyzing case studies of how to mobilize ddata analysis for justice and equity
Mimi Onuoha
- Nigerian American public intellectual
- artist who creates public and tactile interactive art exhibitions
- data processes is the main subject of her art
Important Things to Remember
- Data is subjective
- Humanities focuses on subjectivity and the subjective. A humanistic perspective reveals this and also uses art and humanistic methods to explore subjectivity in the midst of data and datafication
- Data is social
- Looking at missing datasets allows us to think about what does the social have to do with the subjective
- Data and all forms of knowledge and information are inherently and irreducibly social
- Art dissects data’s apparent objectivity and integrates technical and humanistic knowledge in order to expose the internal logics of progress and data
Important Questions and Provocations
- “Missing” is a visual reflection and critique of exclusion in data set
- “What is missing is always there”
- What is the difference between missing data and a missing dataset?
- What are some reasons why Data can be missing?
- Missing data sets are blank spots that exist in spaces that ar otherwise data saturated
- Chat GPT is not god, one should not apply a theistic notion to data or technology
Related Books/Papers
- Engineering Knowledge by Diane Forsythe discusses the history and knowledge practices of the Knowledge Engineering and Expert Systems movement